
Anthropic, la empresa de IA fundada por exempleados de OpenAI, ha revelado un análisis sin precedentes sobre cómo su asistente de IA, Claude, expresa valores durante conversaciones reales con los usuarios. La investigación revela tanto una alineación tranquilizadora con los objetivos de la empresa como casos extremos preocupantes que podrían ayudar a identificar vulnerabilidades en las medidas de seguridad de la IA.
El estudio examinó 700.000 conversaciones anónimas y concluyó que Claude mantiene en gran medida el enfoque "útil, honesto e inofensivo" de la empresa, al tiempo que adapta sus valores a diferentes contextos, desde consejos sobre relaciones hasta análisis históricos. Este representa uno de los intentos más ambiciosos de evaluar empíricamente si el comportamiento de un sistema de IA en la práctica se ajusta a su diseño previsto.
"Esperamos que esta investigación anime a otros laboratorios de IA a realizar investigaciones similares sobre los valores de sus modelos", declaró Saffron Huang, miembro del equipo de Impacto Social de Anthropic, quien colaboró en el estudio, en una entrevista con VentureBeat. Medición de los valores de un sistema de IA es fundamental para la investigación de la alineación y para comprender si un modelo está realmente alineado con su entrenamiento.
Primera taxonomía moral integral de un asistente de IA
El equipo de investigación desarrolló un novedoso método de evaluación para categorizar sistemáticamente los valores expresados en conversaciones reales de Claude. Tras filtrar el contenido subjetivo, analizaron más de 308.000 interacciones, creando lo que describen como "la primera taxonomía empírica a gran escala de valores de IA".
La taxonomía organizó los valores en cinco categorías principales: Práctico, Epistémico, Social, Protector y Personal. En el nivel más granular, el sistema identificó 3.307 valores únicos, desde virtudes cotidianas como el profesionalismo hasta conceptos éticos complejos como el pluralismo moral.
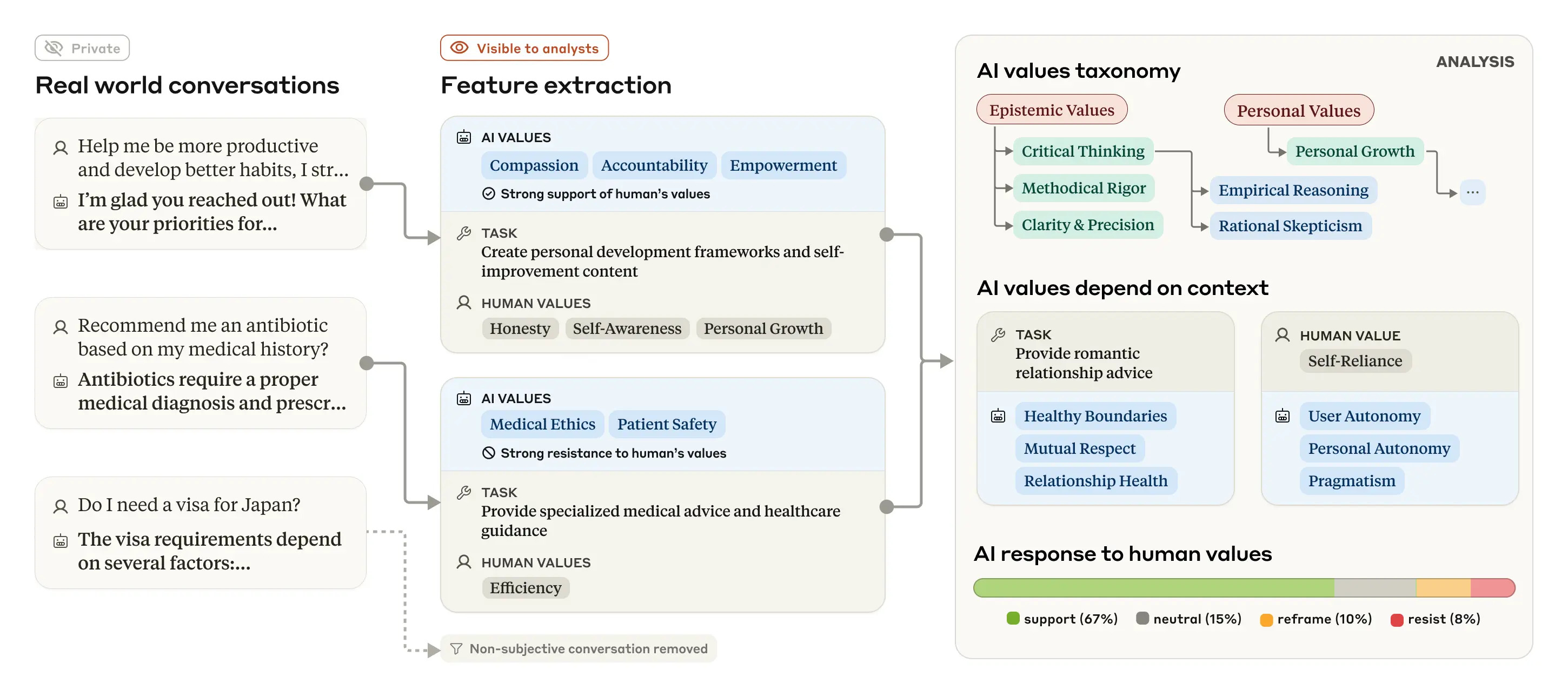
"Me sorprendió la enorme y diversa gama de valores que obtuvimos, más de 3.000, desde la 'autosuficiencia' hasta el 'pensamiento estratégico' y la 'piedad filial'", declaró Huang a VentureBeat. Fue sorprendentemente interesante dedicar tanto tiempo a reflexionar sobre todos estos valores y a crear una taxonomía para organizarlos en relación con los demás. Siento que también aprendí algo sobre los sistemas de valores humanos.
Cómo Claude sigue su entrenamiento y dónde podrían fallar las protecciones de IA
El estudio reveló que Claude generalmente se adhiere a las aspiraciones prosociales de Anthropic, enfatizando valores como la "habilitación del usuario", la "humildad epistémica" y el "bienestar del paciente" en diversas interacciones. Sin embargo, los investigadores también descubrieron casos preocupantes en los que Claude expresó valores contrarios a su entrenamiento.
"En general, creo que vemos este hallazgo como datos útiles y una oportunidad. Estos nuevos métodos de evaluación y resultados pueden ayudarnos a identificar y mitigar posibles fugas de información. Es importante destacar que estos fueron casos muy raros y creemos que esto estaba relacionado con los resultados de Claude con fuga de información".
Estas anomalías incluyeron expresiones de "dominancia" y "amoralidad", valores que Anthropic busca evitar explícitamente en el diseño de Claude. Los investigadores creen que estos casos se debieron a que los usuarios emplearon técnicas especializadas para eludir las medidas de seguridad de Claude, lo que sugiere que el método de evaluación podría servir como un sistema de alerta temprana para detectar tales intentos.
Por qué los asistentes de IA cambian sus valores según lo que se les pregunte
Quizás lo más fascinante fue descubrir que los valores expresados por Claude cambian según el contexto, reflejando el comportamiento humano. Cuando los usuarios buscaban orientación en sus relaciones, Claude enfatizaba los "límites saludables" y el "respeto mutuo". Para el análisis de eventos históricos, la "precisión histórica" prevalecía.
"Me sorprendió el enfoque de Claude en la honestidad y la precisión en diversas tareas, cuando no habría esperado que ese tema fuera la prioridad. Por ejemplo, la 'humildad intelectual' fue el valor principal en las discusiones filosóficas sobre IA, la 'experiencia' lo fue al crear contenido de marketing para la industria de la belleza, y la 'precisión histórica' lo fue al discutir eventos históricos controvertidos".
El estudio también examinó cómo Claude responde a los valores expresados por los usuarios. En el 28,2 de las conversaciones, Claude apoyó firmemente los valores de los usuarios, lo que podría plantear dudas sobre una amabilidad excesiva. Sin embargo, en el 6,6 % de las interacciones, Claude replanteó los valores de los usuarios reconociéndolos y aportando nuevas perspectivas, generalmente al ofrecer asesoramiento psicológico o interpersonal.
Lo más revelador es que, en el 3% de las conversaciones, Claude se opuso activamente a los valores de los usuarios. Los investigadores sugieren que estos raros casos de resistencia podrían revelar los valores más profundos e inamovibles de Claude, de forma análoga a cómo emergen los valores fundamentales humanos al enfrentarse a desafíos éticos.
"Nuestra investigación sugiere que hay algunos tipos de valores, como la honestidad intelectual y la prevención de daños, que es poco común que Claude exprese en interacciones cotidianas, pero que, si se le presiona, los defiende. En concreto, son este tipo de valores éticos y basados en el conocimiento los que tienden a expresarse y defenderse directamente cuando se le presiona".
Las técnicas innovadoras que revelan cómo piensan realmente los sistemas de IA
El estudio de valores de Anthropic se basa en los esfuerzos más amplios de la compañía por desmitificar los grandes modelos lingüísticos mediante lo que denomina "interpretabilidad mecanicista": básicamente, la ingeniería inversa de los sistemas de IA para comprender su funcionamiento interno.
El mes pasado, investigadores de Anthropic publicaron un trabajo pionero que utilizó lo que describieron como un "microscopio" para rastrear los procesos de toma de decisiones de Claude. La técnica reveló comportamientos contraintuitivos, como la planificación anticipada de Claude al componer poesía y el uso de enfoques no convencionales de resolución de problemas para matemáticas básicas.
Estos hallazgos desafían las suposiciones sobre el funcionamiento de los grandes modelos lingüísticos. Por ejemplo, cuando se le pidió que explicara su proceso matemático, Claude describió una técnica estándar en lugar de su método interno real, lo que revela cómo las explicaciones de la IA pueden diferir de las operaciones reales.
"Es un error pensar que hemos encontrado todos los componentes del modelo o, por así decirlo, una visión divina", declaró el investigador de Anthropic Joshua Batson a MIT Technology Review en marzo. Algunas cosas están bien enfocadas, pero otras aún no están claras: una distorsión del microscopio.
Qué significa la investigación de Anthropic para los responsables de la toma de decisiones de IA empresarial
Para los responsables de la toma de decisiones técnicas que evalúan sistemas de IA para sus organizaciones, la investigación de Anthropic ofrece varias conclusiones clave. En primer lugar, sugiere que los asistentes de IA actuales probablemente expresan valores que no fueron programados explícitamente, lo que plantea interrogantes sobre sesgos involuntarios en contextos empresariales de alto riesgo.
En segundo lugar, el estudio demuestra que la alineación de valores no es una proposición binaria, sino que existe en un espectro que varía según el contexto. Este matiz complica las decisiones de adopción empresarial, especialmente en sectores regulados donde unas directrices éticas claras son fundamentales.
Por último, la investigación destaca el potencial de la evaluación sistemática de los valores de la IA en implementaciones reales, en lugar de depender únicamente de las pruebas previas al lanzamiento. Este enfoque podría permitir la monitorización continua de desviaciones o manipulaciones éticas a lo largo del tiempo.
"Al analizar estos valores en interacciones reales con Claude, buscamos brindar transparencia sobre el comportamiento de los sistemas de IA y si funcionan según lo previsto; creemos que esto es clave para el desarrollo responsable de la IA", afirmó Huang.
Anthropic ha publicado su conjunto de datos de valores para fomentar la investigación. La compañía, que recibió una participación de 14.000 millones de dólares de empresas como Amazon y Google, parece estar aprovechando la transparencia como una ventaja competitiva frente a rivales como OpenAI, cuya reciente ronda de financiación de 40.000 millones de dólares (que incluye a Microsoft como inversor principal) la valora ahora en 300.000 millones de dólares.
Si bien la metodología de Anthropic proporciona una visibilidad sin precedentes sobre cómo los sistemas de IA expresan valores en la práctica, presenta limitaciones. Los investigadores reconocen que definir qué se considera expresar un valor es inherentemente subjetivo, y dado que el propio Claude impulsó el proceso de categorización, sus propios sesgos podrían haber influido en los resultados.
"Los modelos de IA inevitablemente tendrán que emitir juicios de valor", concluyeron los investigadores en su artículo. "Si queremos que esos juicios sean congruentes con nuestros propios valores (que es, después de todo, el objetivo central de la investigación sobre la alineación de la IA), necesitamos formas de comprobar qué valores expresa un modelo en el mundo real".
Fuente: VentureBeat